STM32F1系列结构

- AHB总线矩阵
- ICode总线:访问Flash的代码段
- DCode总线:访问Flash的只读数据段(常量、静态变量、全局变量)
- System总线:访问整个内存空间,一般用于任意访存
- AHB挂载4主3从
- 主:DCode、System、DMA1、DMA2
- 从:DCode2Flash、SRAM、AHB总线(包括AHB-APB1和AHB-APB2)
- DMA数据流向
- 外设->存储器:AHB/APB1/APB2总线->DMA通道->AHB总线矩阵->Flash或SRAM
- 存储器->外设:Flash或SRAM->AHB总线矩阵->DMA通道->AHB总线矩阵->AHB/APB1/APB2总线
-
存储器->存储器:Flash或SRAM->AHB总线矩阵->DMA通道->AHB总线矩阵->Flash或SRAM
-
DMA结构
- 有多个DMA请求时,分配到对应的通道中,进行仲裁(先软件再硬件),最后按优先级执行通道传输
- DMA请求源和分配的通道的映射是固定的,会有一张映射表
STM32F4系列结构
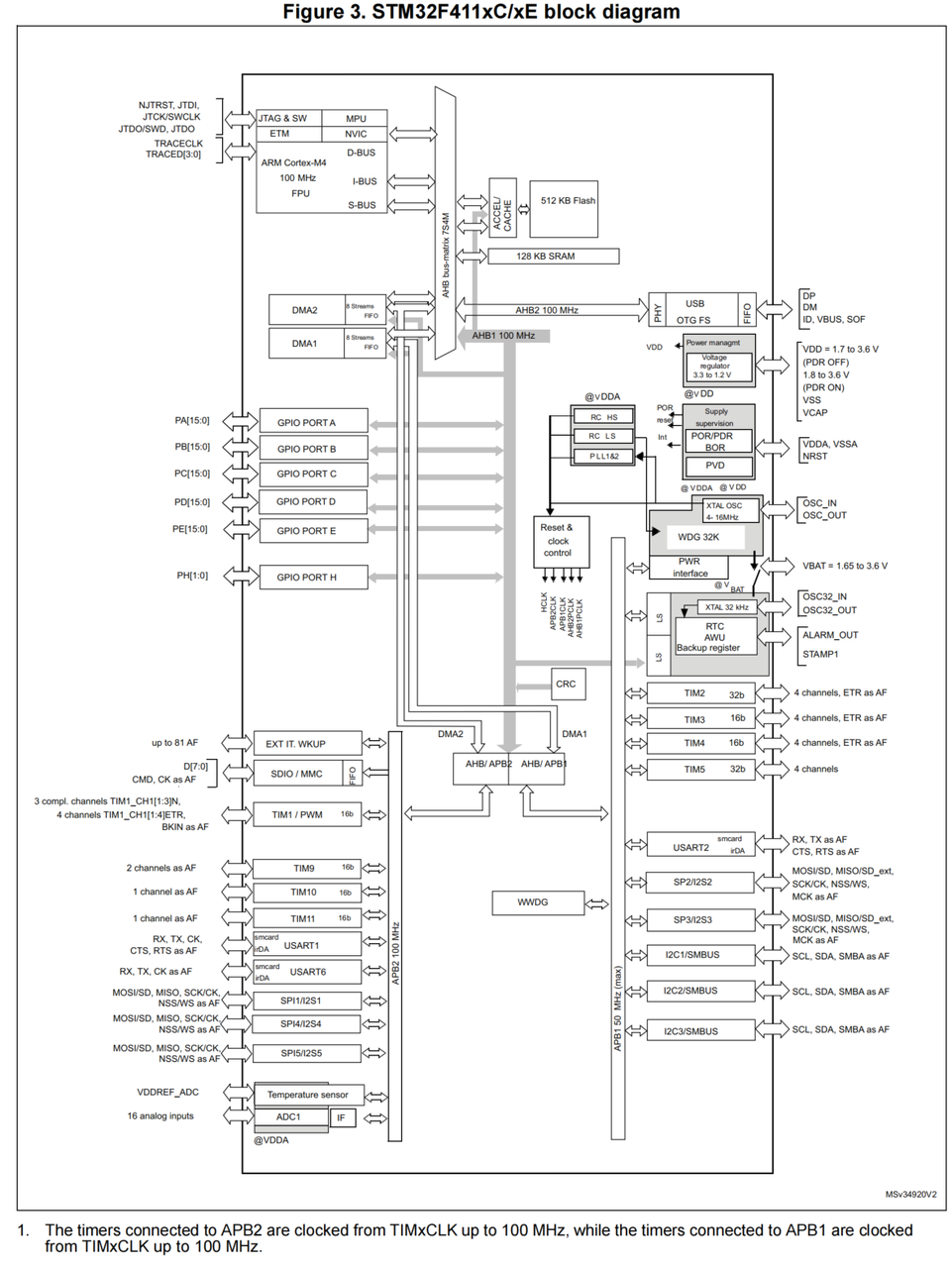

- AHB总线矩阵

-
ICode总线:访问Flash的代码段
-
DCode总线:访问Flash的只读数据段(常量、静态变量、全局变量)
-
System总线:访问整个内存空间,一般用于访存
-
AHB总线矩阵:挂载了6主5从
- 主:ICode、DCode、System、DMA1Memory、DMA2Memory、DMA2Peripheral
- 从:ICode2Flash、DCode2Flash、SRAM、AHB总线(包括AHB-APB1和AHB-APB2)
-
DMA结构
-
DMA2挂载方式
- 存储器端口:AHB总线矩阵
- 外设端口:AHB总线矩阵、AHB-APB2
- DMA1挂载方式
- 存储器端口:AHB总线矩阵
- 外设端口:AHB-APB2
- DMA1与DMA2区别
- 只有DMA2可以完成“存储器-存储器”的传输
- DMA2速度比DMA1快
- DMA的Stream结构

- 多个通道请求对应一个流请求
- 有多个DMA流请求时,进行仲裁(先软件再硬件),最后按优先级执行stream传输
- DMA流请求和分配的stream的映射是固定的,会有一张映射表
- 流传输时,使用FIFO进行暂存
- DMA的Burst传输
- 一次Burst传输=多个DMA单次传输(这里的“多个”就是“Burst大小”)
- 多个DMA单次传输可能会被打断,但一次Burst传输无法被CPU打断
- 作用:让DMA独占AHB总线,实现DMA传输的原子操作
GPIO+DMA
- GPIO输出数据原理:将占空比为$K_0$的周期波形记为比特0,将占空比为$K_1$的周期波形记为比特1。
- GPIO输出数据的常见方式
- 阻塞delay或关中断方式:软件控制GPIO翻转,会导致完全占用CPU
-
TIM输出可变占空比的PWM:每次输出完一个bit,就会产生一次更新中断,在中断中修改CCR,以产生下次的PWM波形,会导致切换上下文代价过大
-
解决方法:TIM+DMA输出可变占空比的PWM
- TIM每次输出完一个bit,不会更新中断(IT位),只会产生更新事件(FLAG位)作为DMA请求源,由DMA来更新CCR
USART串口+DMA
- 常见使用方式的缺点
- 轮询+单缓冲:CPU浪费;实时性差,若轮询间隔>串口字节间隔,会导致丢数据。
- 串口字节中断+单缓冲:如果波特率高,会导致中断次数多,上下文切换代价太大。
- DMA全满中断+单缓冲:若DMA接收间隔>DMA转移间隔,会导致缓冲区覆盖而丢数据。
- 解决方法:DMA半满/全满中断+双缓冲+环形队列+串口空闲中断
-
串口空闲中断
- USART每次接收一个字节不会产生字节中断(IT位),而是产生字节事件(FLAG位)作为DMA请求源
- 若串口空闲,代表该帧数据全部传完,此时才会触发一次中断,可以减少中断次数
-
DMA半满/全满中断+双缓冲+环形队列
- 假设半满时接收到的数据量为$N_{half}$
- 双缓冲(A-B buffer):设置一个buffer[N],将前$N_{half}$作为buf0,剩余部分作为buf1。一开始往buf0存,半满后会存储到buf1;全满时手动切换回buf开头,即存储到buf0。
- 环形队列:由于双缓冲机制,会导致每次存储的数据长度不同,所以使用环形队列来存储不定长数据。
传输实现

- 第一种情况(触发空闲中断,未触发半满中断):在空闲中断中将buf0拿到环形队列
- 第二种情况(触发半满中断后,触发空闲中断,未触发全满中断):先在半满中断中将buf0拿到环形队列,再在空闲中断中将buf1拿到环形队列
- 第二种情况(触发半满中断后,触发全满中断):先在半满中断中将buf0拿到环形队列,再在全满中断中将buf1拿到环形队列
- getDMARemainSize():返回DMA剩余空间
- handledSize:已经处理过的数据量
-
pendingSize:待处理的数据量
-
空闲中断函数
- 计算pendingSize = getDMARemainSize() - handledSize
- 将==buf[handledSize]之后==的==pendingSize大小的数据==放到环形缓冲区
- 更新handledSize = handledSize + pendingSize
- 半满中断函数:同理
- 全满中断函数:同理,但需要将handledSize = 0(表示回到buf开头)
串口协议实现
-
串口协议:帧LUT定义
-
注册回调:回调函数的LUT定义、注册函数
```c // 回调函数LUT的表项定义 typedef struct{ FuncPtr handler, // 定义和handler相关的信息 } LUTItem; typedef LUTItem LUT;
// 回调函数LUT定义 FuncPtr handler1 = NULL; FuncPtr handler2 = NULL; FuncPtr handler3 = NULL; LUT lut[] = { {handler1,...}, {handler2,...}, {handler3,...}, };
// 注册函数定义 void CallbackRegister(int idx, FuncPtr newHandler){ lut[idx].handler = Handler; }
// 使用回调函数 void AnyFunc(...){ int lutSize = sizeof(lut)/sizeof(lut[0]); for(int i=0;i<lutSize;i++){ lut[i].handler(); } } ```
总结
- 传输数据的进化过程
- 轮询
- 频繁产生中断
- 频繁产生事件+DMA半满/全满中断+单缓冲区
- 频繁产生事件+DMA半满/全满中断+双缓冲区+环形队列
- 频繁产生事件+DMA半满/全满中断+双缓冲区+环形队列+DMA的Burst模式